Processing Large Documents in Dell Boomi
We’ve worked with a number of integration platforms over the years. BizTalk, LogicApps and Dell Boomi through to SSIS and niche service applications such as ServiceStack.
Dell Boomi iPaaS software is an excellent platform for manipulating and processing large volumes of small documents, especially in conjunction with clustered RabbitMQ, Kafka or other event based systems. However, there are occasions when batch is necessary. Architecturally, you could apply a debatching process using either Boomi’s Connector Operation functions and alignment with a grouping field and then process using Boomi’s Map component. This still may add some additional efficieny overhead as each component the process iterates through incurs some overhead e.g. a Try/Catch even if it’s not transforming a document incurs overhead.
There are some situations where the ability to process a large number of records quickly are useful:
- Where the upstream process is able to function faster in batch mode when transferring records e.g. Cloud CRM platforms such as Dynamics CRM. In this case it might actually be slower to debatch and rebatch to target.
- Creating or maniuplating data e.g. a windowing function in SQL to return batchable data is less performant that just extracting the data
- Having the same process run full cache and cache delta refreshes e.g. to Redis
Often you might have multiple solutions within your solution stack. For example, you may architecturally determine to use SQL Service Integration Services (SSIS) to perform the batch function and Dell Boomi perform the message and eventing integration functions. Using this approach, you can have Dell Boomi perform both functions, and in some cases, batch process large documents and transformations faster than SSIS.
Boomi Performance
When even medium dataset sizes through Boomi Map components you may notice that process execution time rapidly increases, especially when a large number of rows are involved or there is a deep level of nesting e.g. going from a flat database structure to a nested XML structure. In some cases, if you’re transferring data from SQL to another target system or publishing via an API, it’s faster to run the FOR XML statement in SQL Server and return a single semi-ordered document rather than multiple rows. The introduction this year of the XSLT Script component as part of the Data Process component presented an opportunity to test a number of processing scenarios. In-line XSLT processing was available previously by using Groovy scripting, but this is a cleaner approach.
Test Server
Dell Boomi 20.05 On Premise
Windows Server 2012 (VMWare Virtual Machine)
8 Intel Xeon E5-2680 v3 CPU Cores
16 GB RAM
Scenarios
Transform 1m SQL Records of (10 columns wide, mixed type including int, long, nvarchar and datetime2) using the standard Boomi DB Connector and the Converting to a JSON array using the standard Map Connector
Transform 1m SQL Records of (10 columns wide, mixed type including int, long, nvarchar and datetime2) using the standard Boomi DB Connector and the Converting to a JSON array using the XSLT Script Component
Transform 1m SQL Records of (10 columns wide, mixed type including int, long, nvarchar and datetime2) using the standard Boomi DB Connector and the Converting to a JSON array using the Saxon XSLT transform function
In all instances, the stored procedure returning the data to the Boomi DB connector was returning the data from Schema Only Memory Optimised SQL tables.
Results
Before the start of each scenario run, the Boomi instance was restarted to completely flush the heap. There we’re a number of other scheduled processes and tasks running, but nothing significantly detrimental to the overall performance of the server.
Scenario 1
This was the slowest transformation (attempted transformation). After leaving running for over 12 hours, I killed the process and restarted the instance. I ran the scenario for a second time with the same result. The information in the logs showed that all the time was being consumed by the Map component.
Scenario 2
This was the first time we got “measureable” results. Our best run in this scenario was 3 hours and 28 minutes. Although I’m not detailing the specific set-up in this posting, the direct translation from the Boomi DB byte array to JSON involved inserting the returned DB records into Dynamic Process Property Transferring this 130MB byte array into memory took 3 hours and 26 minutes of the overall process. Another way to do this could be to process the raw DB document through each of the components like a normal document after wrapping some XML tags around it (more on that later) but moving this heave document even through something like a Try/Catch or Set Properties was too slow. It would spend 15-30 seconds just transiting through these components even without document manipulation.
Scenario 3
1 minute and 30 seconds for a million records! This was for the whole process to complete including database retrieval, transformation, transfer and clean-up. Win!! Deltas for less than a million records we’re significantly faster.
How To Build Scenario 3

Boomi Process for Large Dataset Processing
1. Initialising the Process
To help control the overall function, we use a number of Process Properties
- StylesheetExecutionDirectory [string] The directory that contains the JAR file to the Saxon XML processor which you can download from here. Unzip the downloaded files into this directory.
- StylesheetOutputDirectory [string] The location we want to save the result of the transformation, in this case a JSON file
- StylesheetInputDirectory [string] The location that we save the results of the db connector and the XML control file.
- StylesheetDirectory [string] The location of the .xsl or .xslt file that we use to perform the transformation
- Stylesheet [string] The name of the stylesheet to be executed
- HeapSpaceAllocation [number] The amount in megabytes to assign to the Saxon processor to transform the document. In the case of these million records which was approximately 110MB in size pre-transformation, it was consuming about 1.6GB of memory. We set this value to 2048. You may need to set it higher if you're consuming or processing bigger documents.
In this step, I also set a number of variables to use later in the process:
- DDP_DB_Output_Name ["Unique Value", "Static value of '.db']: Used to create a dynamic file name for the returned database output e.g. 7983209519155733431.db
- DDP_XML_Variables_Name ["Unique Value", "Static value of '.xml']: Used to create the XML file that feeds input into the stylesheet transformation
- DDP_JSON_Name ["Unique Value", "Static value of '.json']: Name for the transformed output. JSON in this example but could be anything like seperated values, XML, SVG etc.
2. Serialise to Disk
So far, it’s been pretty standard Boomi, execution of a stored procedure to return a result sent, and in this case I’m also returning an In/Out property in addition to the records returned.
The Boomi DB return format is being serialised to disk in this step of the process with no transformation directly in Boomi. Below is an example of a single record returned by the DB connector for Boomi. I’ve deliberately chosen a DB example to demonstrate that you can use XSLT to transform more than just XML documents, especially when using Version 2.0 or Version 3.0 of the transformation engine.
DBSTART|d07df249-1a3e-4252-a344-0d384c784969|2|@|BEGIN|2|@|OUT_START|11|@|23.0000000000000000|^|nnz|^|000|^|aaa|^|200|^|ONE|^|00000|^|00000/000/aaa|^|00000/000/aaa/250/23.00|^|20200511 083637.297|#||#|OUT_END|11|@|OUT_START|23|@|-903871796|#||#|OUT_END|23|@|END|2|@|DBEND|d07df249-1a3e-4252-a344-0d384c784969|2|@|The pieces I'm most interested in this document are:
This section which denotes the each row being returned. In this example, it's just single record. We can use the OUT_START|11| section to denote the start and end of the records.
|OUT_START|11|@|23.0000000000000000|^|nnz|^|000|^|250|^|200|^|aaa|^|00000|^|00000/000/aaa|^|00000/000/aaa/250/23.00|^|20200511 083637.297|#||#|OUT_END|11|This section which denotes any output variables with |OUT_START|23| as returned by a stored procedure. In this example, I'm actually just using the out of the box functionality to return the output result into a Dynamic Document Property, but equally, you can extract then from the returned DB file.
|OUT_START|23|@|-903871796|#||#|OUT_END|23|3. Control File to Execute XSLT
There are two advantages to generating an XML file for the purpose of trigger the style sheet transformation:
- The obvious one is that it's much easier to trigger an apply-template in the style sheet with an XML file
- The second is that I'm taking advantage of Boomi to insert any other attributes or data into the XML that I can merge with the existing dataset. It gives me the same ability you have with using a document cache in a Map component
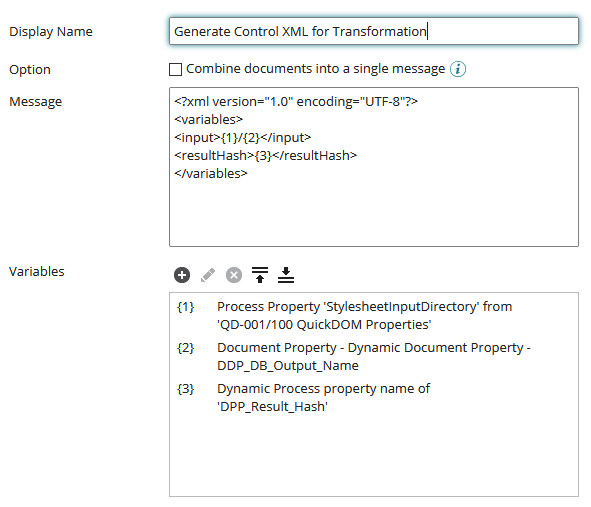
XML Control Message Creation
Example XML Output:
<?xml version="1.0" encoding="UTF-8"?>
<variables>
<input>\\path\to\database\output\file\2409119373761964557.db</input>
<resultHash>123456789</resultHash>
</variables>We'll see in the XSLT that we can refer to these elements to help control the process in the stylesheet transformation. The most important one is the input element as that defines the path to the source content for the transformation.
4. External XSLT Processing
Instead of processing directly inside of the Boomi heap space, we use the external Saxon XSLT processor through the command line
cmd /c java -Xmx{1}m -jar {2}\saxon-he-10.0.jar -s:{3}\{4} -xsl:{5}\{6} -o:{7}\{8}Process Property 'HeapSpaceAllocation': In this instance it was set to 2048.
Process Property 'StylesheetExecutionDirectory': The location of the Saxon processor, unzipped
Process Property 'StylesheetInputDirectory': The directory where we output the files to be consumed in this process step, the database file and the control XML file
Document Property - Dynamic Document Property - DDP_XML_Variables_Name: The document property containing the name of the XML control file that we created in 3.
Process Property 'StylesheetDirectory': The location where the below style sheet is saved. By having this property driven you could create this as a generic process to be called from other processes.
Process Property 'Stylesheet': The name of the style sheet being executed.
Process Property 'StylesheetOutputDirectory': The location to output the processed files, in this case a JSON transformation
Document Property - Dynamic Document Property - DDP_JSON_Name: The unique name of the JSON file output as a result of the transformation
The Style sheet
Probably the most important piece for this step, is the style sheet that transforms from a non-XML input into non-XML output. Equally, it could be XML for input and/or output if required but the example here demonstrates that there are no limitations to this process. Using the Apache FO processor, PDF’s, graphics and other outputs can be generated in high-performance scenarios. Technically the style sheet below can be processed using V2.0 XSLT processing engines,
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="3.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:fn="http://www.w3.org/2005/xpath-functions">
<!-- The output is set to plain text, but there specific methods in V3.0 for XML, JSON and HTML-->
<xsl:output omit-xml-declaration="yes" method="text" indent="yes"/>
<!-- TThe template match here is against the control XML passed in, it's just triggering the root note. -->
<xsl:template match="/">
<!-- Here we are taking advantage of the control file to bring in the path to the file we want to process -->
<xsl:variable name="input" select="/variables/input/text()"/>
<!-- Beginning the wrapper for the JSON object. The 
 character reference could be excluded (CRLF) if you weren't bothered by JSON formatting and wanted to save a few extra payload bytes -->
<xsl:text>{
"chk": "</xsl:text>
<!-- Here we are taking advantage of the control file to pass in other variables from the process, this could be any value you choose -->
<xsl:value-of select="/variables/resultHash/text()"/>
<xsl:text>",
</xsl:text>
<!-- Beginning an array of JSON objects -->
<xsl:text>"invent": [
</xsl:text>
<!-- The unparsed-text($input) function streams the text from the file into the processor -->
<!-- The regex component of the analyse string is effectively doing a substring extraction. regex="OUT_START\|11\|.*OUT_END\|11\|" -->
<xsl:analyze-string select="replace(unparsed-text($input),'\r','')" regex="OUT_START\|11\|.*OUT_END\|11\|">
<xsl:matching-substring>
<!-- Things to do if there is a string that matches, there is an equivalent non-matching-substring if you wanted to introduce return output for error handing -->
<xsl:variable name="preTrim" select="."/>
<!-- This replaces the start and end of the strings with the |#| seperation character to make it easier for the tokenize (split) function-->
<xsl:variable name="preRows" select="replace(replace($preTrim, 'OUT_START\|[0-9]+\|@\|', '|#|'), '\|#\|\|#\|OUT_END\|[0-9]+\|', '|#|')"/>
<!-- Split on the row deliniation |#| -->
<xsl:variable name="rows" select="tokenize($preRows,'\|#\|')[not(. = '')]"/>
<xsl:for-each select="$rows">
<xsl:call-template name="processRows">
<xsl:with-param name="row" select="."/>
</xsl:call-template>
<!-- Don't put the JSON seperator on the last row for the array -->
<xsl:if test="position() != last()" >
<xsl:text>,
</xsl:text>
</xsl:if>
</xsl:for-each>
</xsl:matching-substring>
</xsl:analyze-string>
<xsl:text>]
}
</xsl:text>
</xsl:template>
<!-- The actual db attribute to JSON attribute happens in this template. Change here to match your output or customise entirely, for example CSV, TSV, YAML etc. -->
<xsl:template name="processRows">
<xsl:param name="row"/>
<xsl:text>{</xsl:text>
<!-- Split on the database column seperator -->
<xsl:variable name="columns" select="tokenize($row,'\|\^\|')[not(. = '')]"/>
<!-- Rather than process in a loop for the columns (which you could if you we're doing a dump routine, match each specific column with the output -->
<xsl:text>"avl": </xsl:text>
<!-- Optionally fomat the output here applying and stylesheet transformations you wish e.g. date/number formattting routines -->
<xsl:value-of select="$columns[1]"/>
<xsl:text>,
</xsl:text>
<xsl:text>"cmp": "</xsl:text>
<xsl:value-of select="$columns[2]"/>
<xsl:text>",
</xsl:text>
<xsl:text>"clr": "</xsl:text>
<xsl:value-of select="$columns[3]"/>
<xsl:text>",
</xsl:text>
<xsl:text>"loc": "</xsl:text>
<xsl:value-of select="$columns[4]"/>
<xsl:text>",
</xsl:text>
<xsl:text>"sit": "</xsl:text>
<xsl:value-of select="$columns[5]"/>
<xsl:text>",
</xsl:text>
<xsl:text>"siz": "</xsl:text>
<xsl:value-of select="$columns[6]"/>
<xsl:text>",
</xsl:text>
<xsl:text>"itm": "</xsl:text>
<xsl:value-of select="$columns[7]"/>
<xsl:text>",
</xsl:text>
<xsl:text>"sku": "</xsl:text>
<xsl:value-of select="$columns[8]"/>
<xsl:text>",
</xsl:text>
<xsl:text>"utc": "</xsl:text>
<xsl:value-of select="$columns[10]"/>
<xsl:text>"
</xsl:text>
<xsl:text>}</xsl:text>
</xsl:template>
</xsl:stylesheet>Although you could argue I’m working around some limitations within Boomi, I like to see this as taking advantage of the best features that Boomi has to offer and taking advantage of the flexibility it provides to drop in some alternative processing options when the need calls. Again, if I was processing single records or small batches, these additional steps would not be necessary. However, when specific speed or volume targets need to be hit, it’s a good option to call on.
Tweaking
If you wanted to process this large input but then de-batch quickly to multiple separate files per row, you can also achieve this in the style sheet by including the result-document processor in your row loop. You will need to ensure that your processRow template in this example is creating valid JSON. Additionally because our input is a byte array, we need to fake a node to be able to pass to the generate-id function. We do this by inserting the returned tokenized row into an XML element in a variable to pass into the generate-id function.
<xsl:for-each select="$rows">
<!-- Create a fake node to work with so we can use the generate-id function to return a unique id-->
<!-- This assumes you have no duplicates across your entire resultset so include an Id or similar from SQL -->
<xsl:variable name="rownode">
<makenode>
<xsl:value-of select="."/>
</makenode>
</xsl:variable>
<!-- Create a unqiue filename based on the unqiue row content -->
<xsl:result-document method="text" href="replace(replace(fn:generate-id($rownode), 'idroot', 'result_'), 'x0', '.json')">
<xsl:call-template name="processRows">
<xsl:with-param name="row" select="."/>
</xsl:call-template>
</xsl:result-document>
</xsl:for-each>Happy transforming!